|
I am currently a tenure-track Associate Professor in the School of Artificial Intelligence at Shanghai Jiao Tong University. Prior to that, I was a postdoctoral researcher at Cornell University, advised by Prof. Noah Snavely. I obtained my Ph.D at Multimedia Lab, Information Engineering, CUHK, supervised by Prof. Dahua Lin. Email / CV / Google Scholar / Github |

|
|
My research broadly spans 3D computer vision, computer graphics, and generative AI. I am also fascinated by how we can understand and interact with the world through diverse modalities and observations that transcend vision and language. If these resonate with you or sparks your curiosity, welcome to reach out via email. |
|
|
|
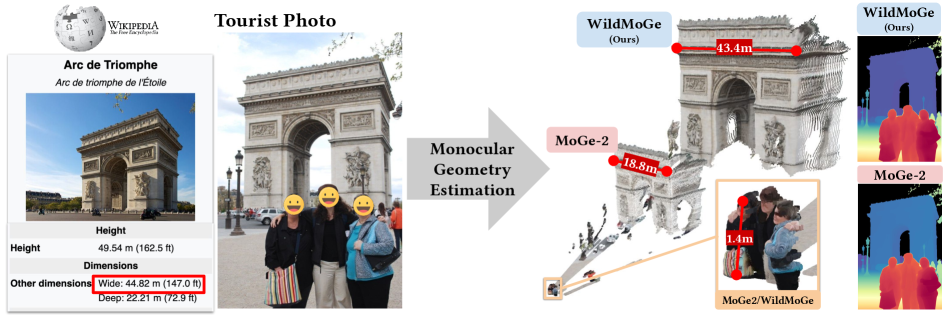
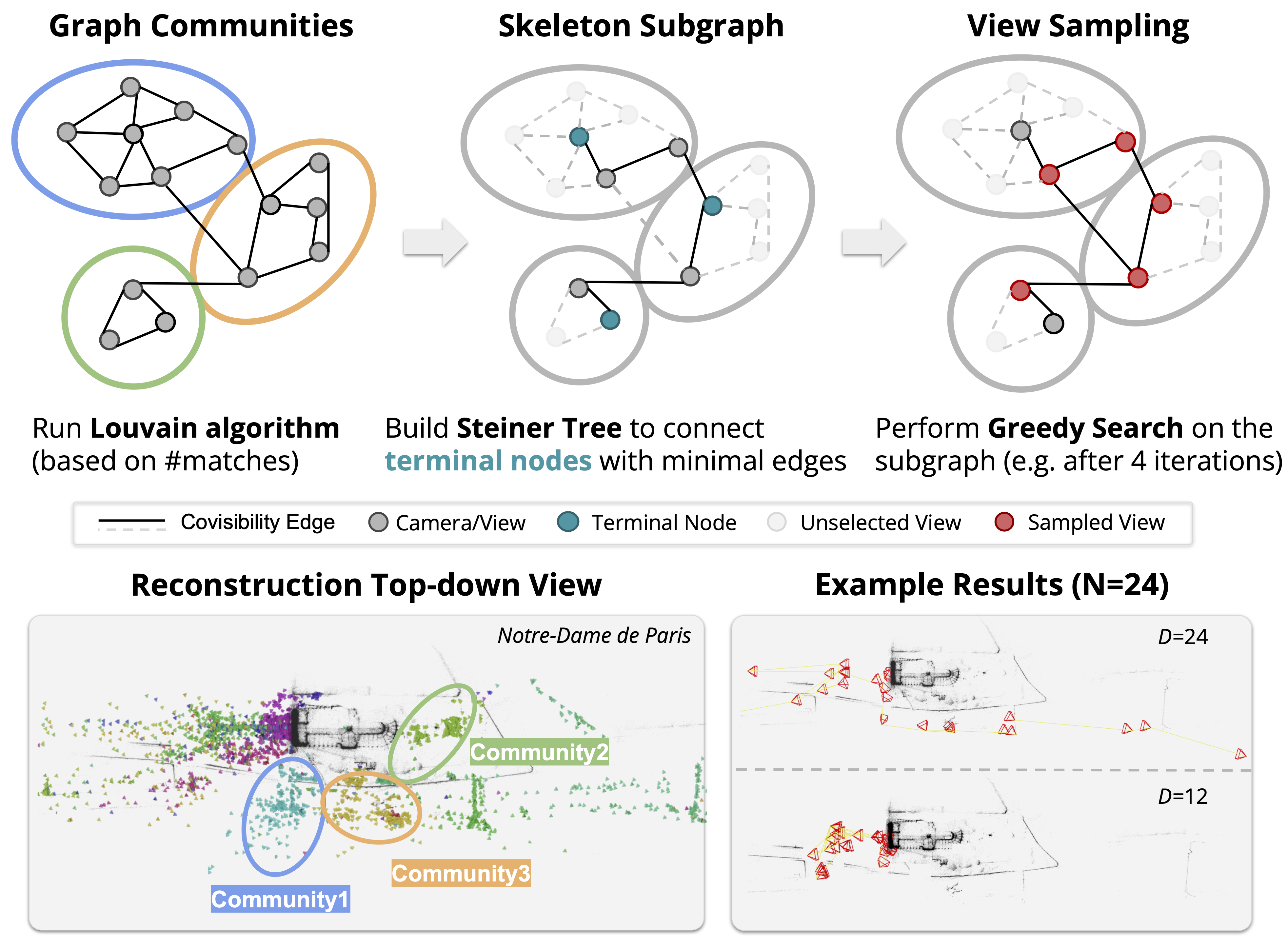
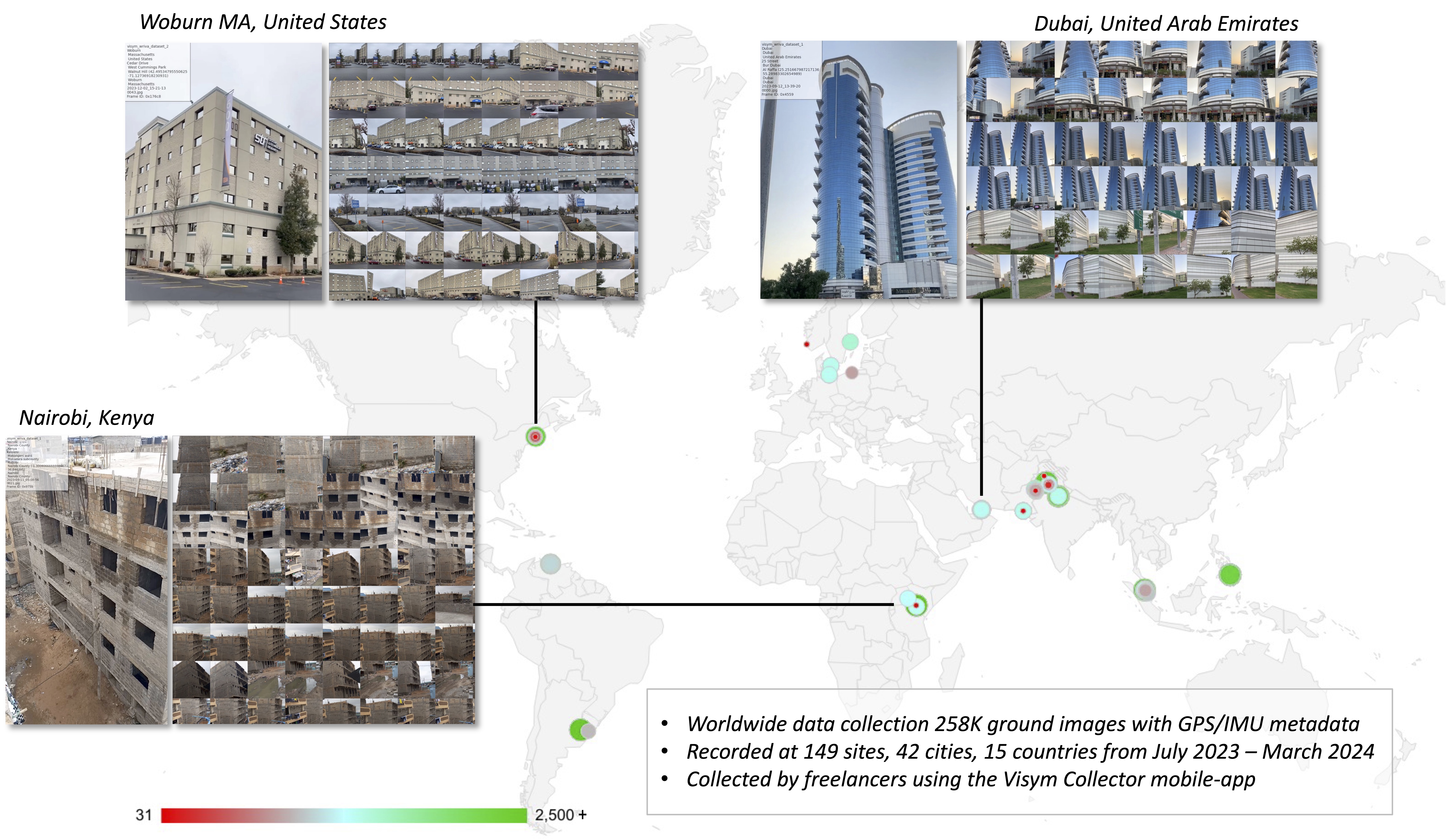
Yuanbo Xiangli, Hanyu Chen, Xueqing Tsang, Noah Snavely ECCV, 2026 project page / paper To address the "scale-collapse" issue in monocular geometry estimation caused by restricted training data, we introduce MetricScenes, a diverse, large-scale dataset with recovered absolute scale, and a novel depth completion algorithm that improves metric accuracy in unconstrained real-world scenarios. |
|
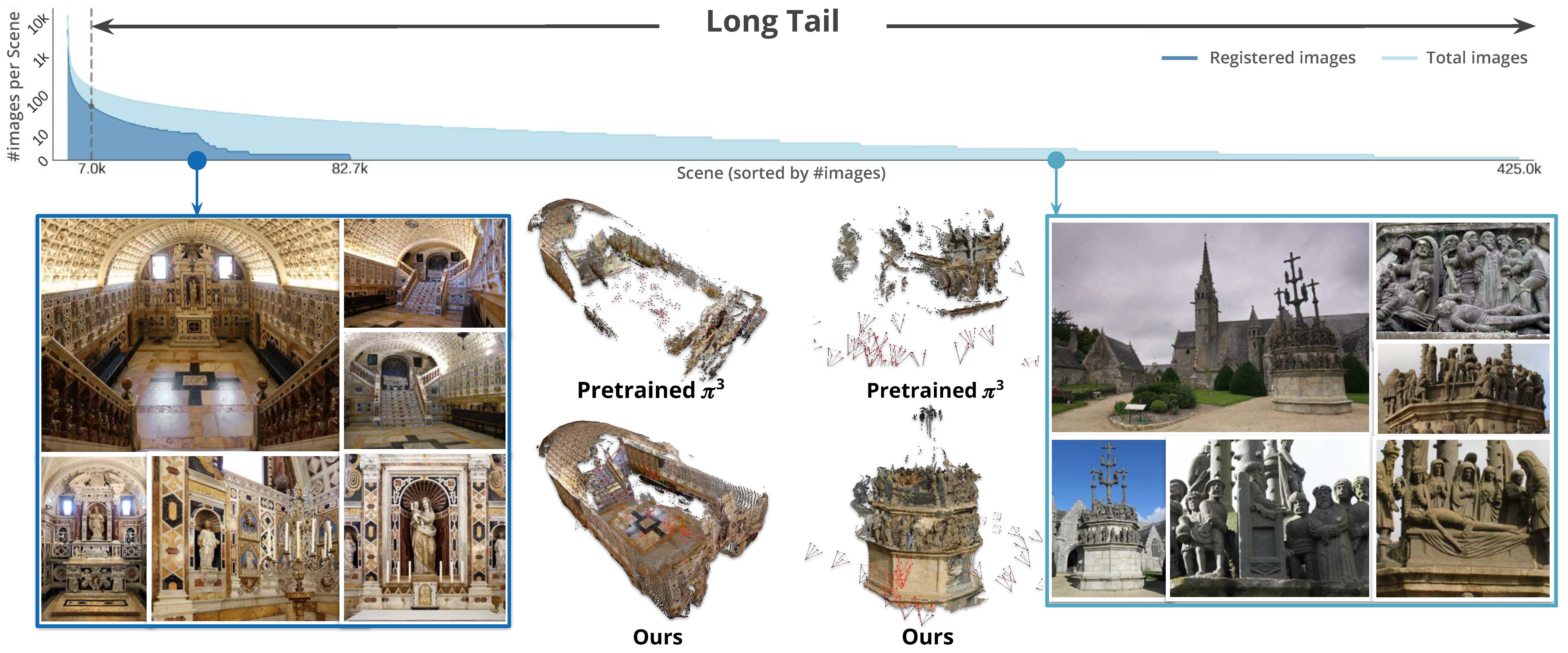
Yuan Li, Yuanbo Xiangli ✉️, Hadar Averbuch-Elor, Noah Snavely, Ruojin Cai ✉️ CVPR, 2026 project page / paper We train more general 3D foundation models for the long tail of noisy, sparse, incomplete Internet photo collections of 3D scenes. Introducing MegaDepth-X, a large new dataset of scenes with high-quality 3D supervision, and a new way of simulating difficult image sets for training. |
|
Yuanbo Xiangli, Ruojin Cai, Hanyu Chen, Jeffrey Byrne, Noah Snavely CVPR, 2025 project page / paper An enhanced pairwise image classifier that tackles visual aliasing (doppelgangers) to improve 3D reconstruction accuracy across diverse, real-world scenes. |
|
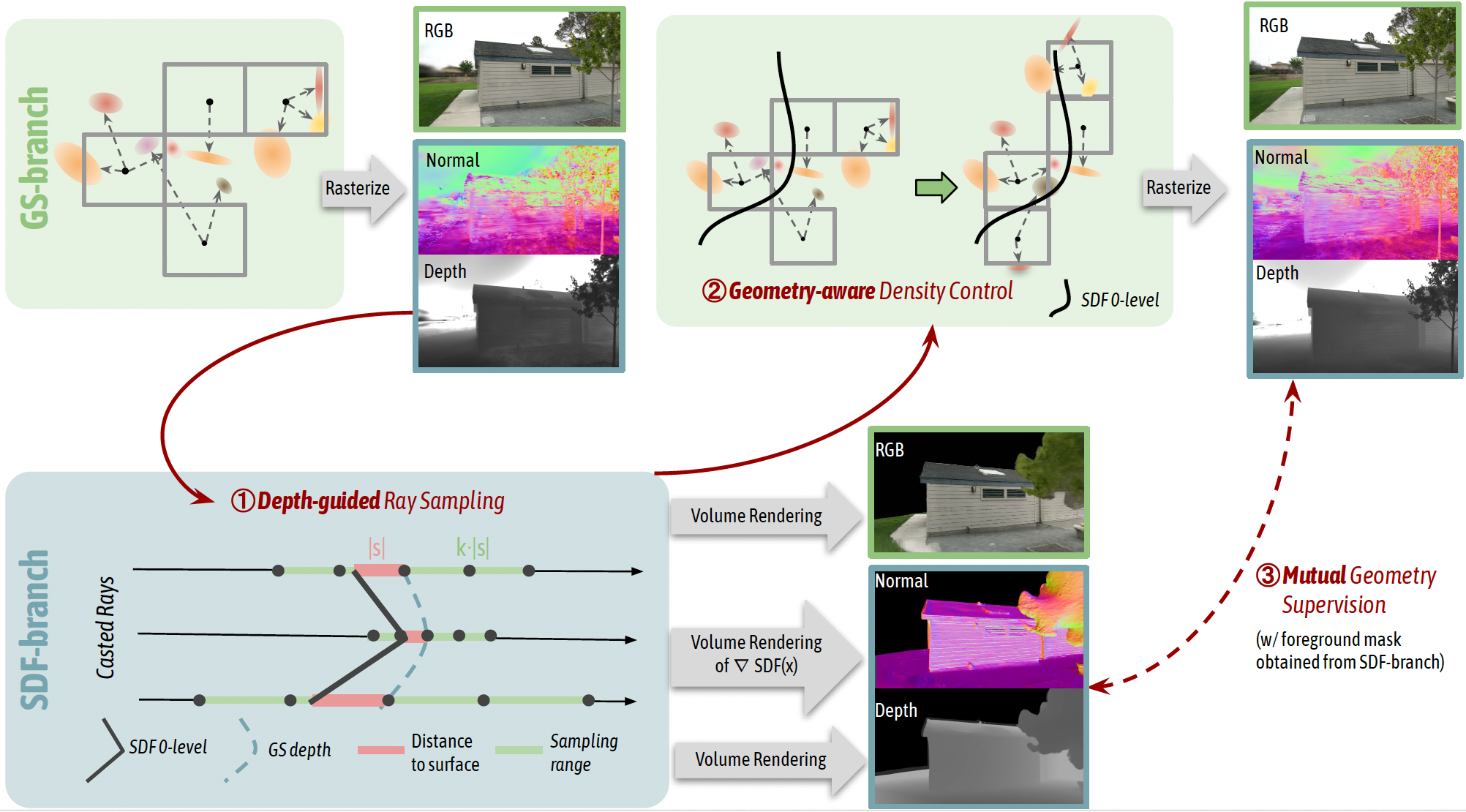
Mulin Yu*, Tao Lu*, Linning Xu, Lihan Jiang, Yuanbo Xiangli ✉️, Bo Dai NeurIPS, 2024 project page / paper A dual-branch system enhances rendering and reconstruction at the same time, with the mutual geometry regularization and guidance between Gaussain primitives and neural surface. |

|
Haian Jin, Yuan Li, Fujun Luan, Yuanbo Xiangli, Sai Bi, Kai Zhang, Zexiang Xu, Jin Sun, Noah Snavely NeurIPS, 2024 project page / paper Neural Gaffer is an end-to-end 2D relighting diffusion model that accurately relights any object in a single image under various lighting conditions. |
|
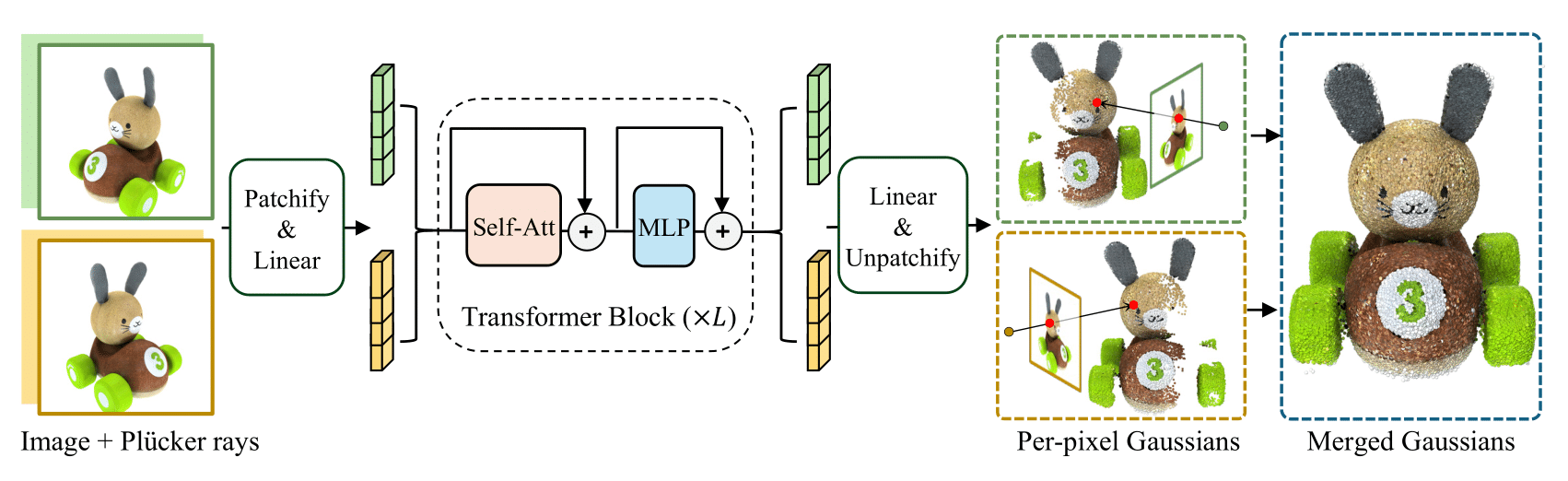
Kai Zhang*, Sai Bi*, Hao Tan*, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, Zexiang Xu ECCV, 2024 project page / paper High-quality 3D Gaussian primitives from 2-4 posed sparse images within 0.23 seconds. |
|
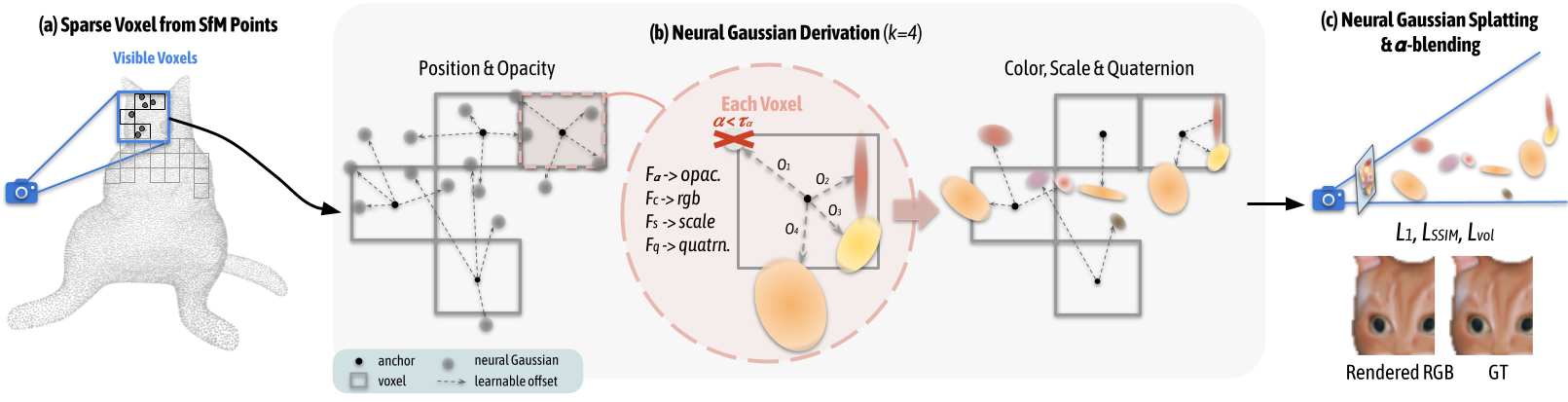
Tao Lu*, Mulin Yu*, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, Bo Dai CVPR, 2024 project page / paper Scaffold-GS uses anchor points to distribute local 3D Gaussians, and predicts their attributes on-the-fly based on viewing direction and distance within the view frustum. |
|
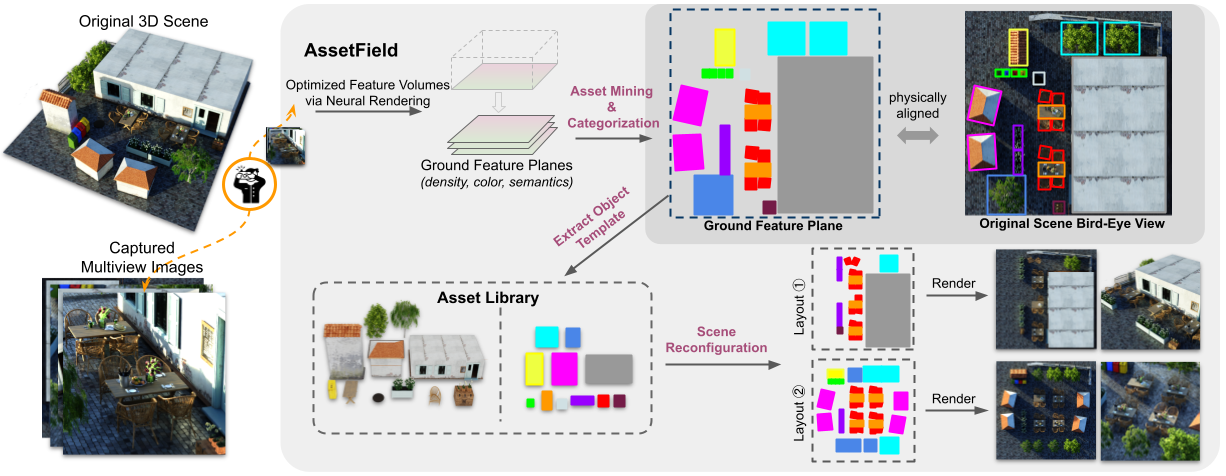
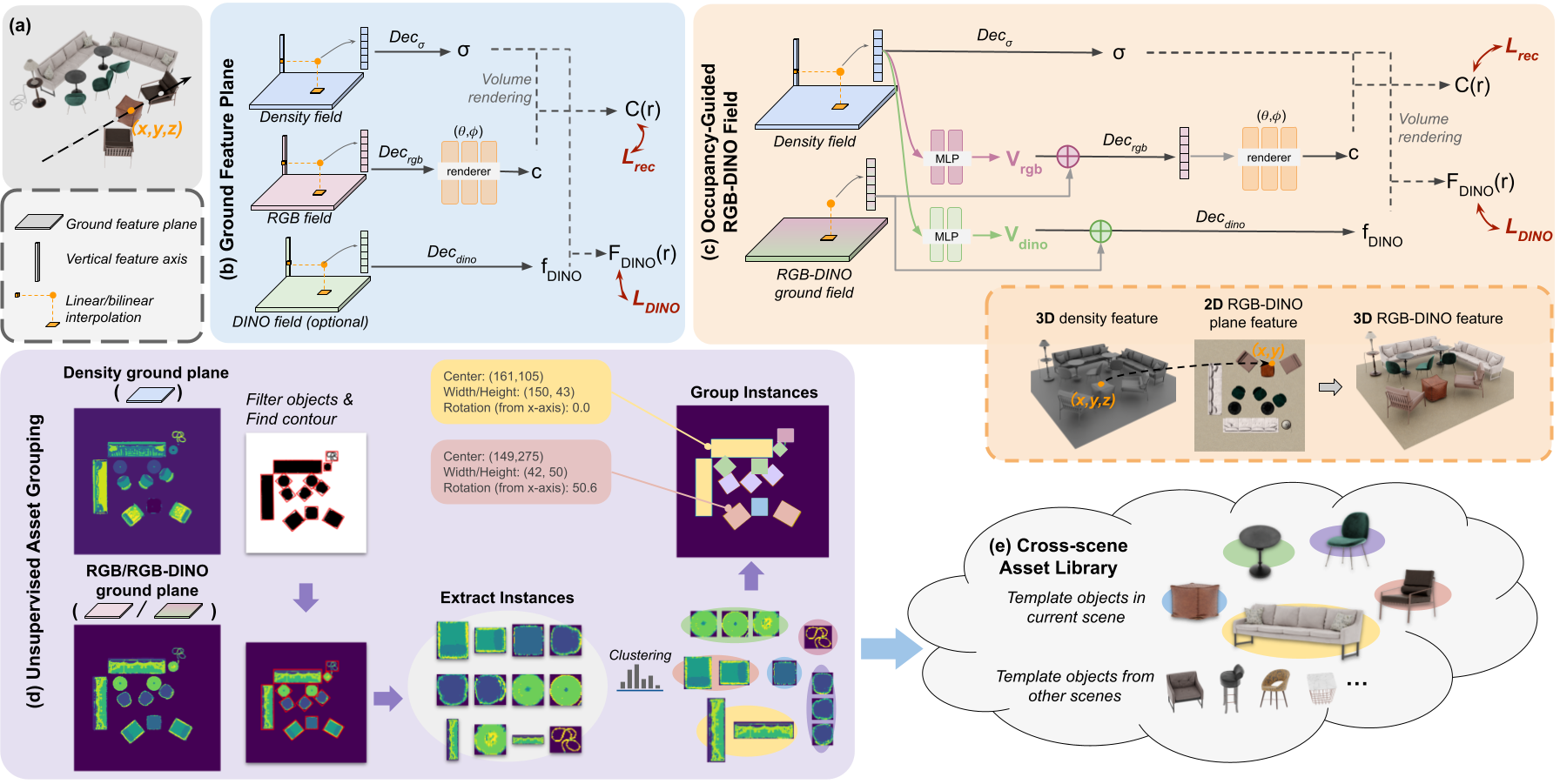
Yuanbo Xiangli*, Linning Xu*, Xingang Pan, Nanxuan Zhao, Bo Dai, Dahua Lin ICCV, 2023 project page / paper A novel neural scene representation that learns a set of object-aware ground feature planes, where an asset library storing template feature patches can be constructed in an unsupervised manner. |

|
Yixuan Li, Lihan Jiang, Linning Xu, Yuanbo Xiangli, Dahua Lin, Bo Dai ICCV, 2023 project page / paper A large-scale, comprehensive, and high-quality synthetic dataset for city-scale neural rendering researches. |
|
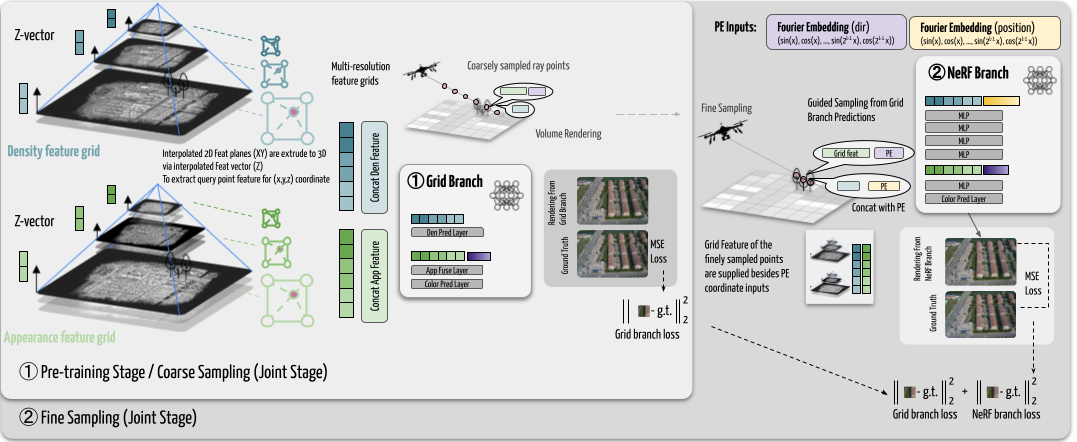
Linning Xu*, Yuanbo Xiangli*, Sida Peng, Xingang Pan, Nanxuan Zhao, Christian Theobalt, Bo Dai, Dahua Lin CVPR, 2023 project page / paper We use grid features to profile the scene and a light-weighted NeRF to pick up details. The two-branch model can produce photo-realistic results with high rendering speed. |
|
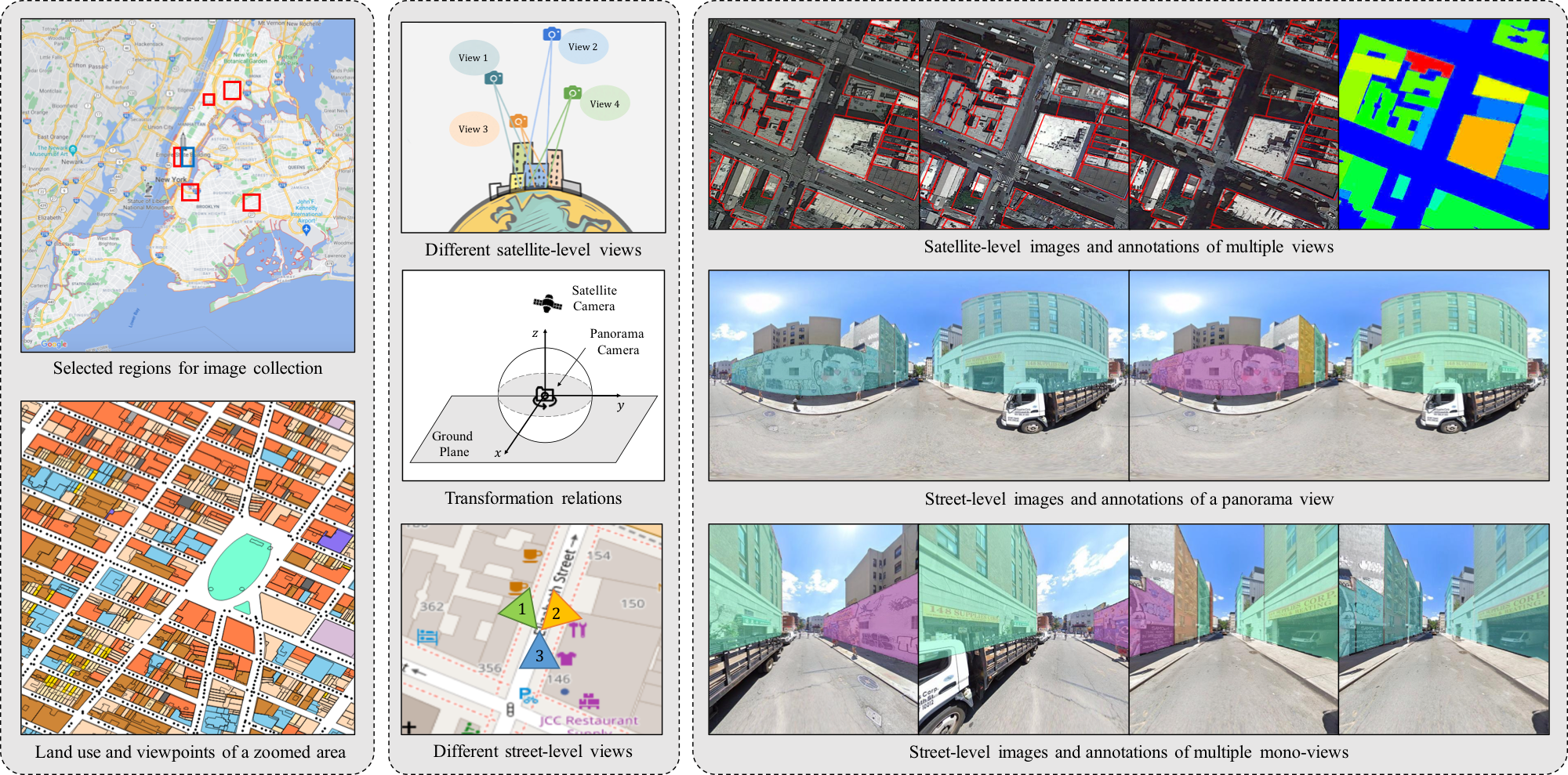
Weijia Li, Yawen Lai, Linning Xu, Yuanbo Xiangli, Jinhua Yu, Conghui He, Guisong Xia, Dahua Lin CVPR, 2023 project page / paper A new dataset containing multi-view satellite images and street-level panoramas, constituting over 100K pixel-wise annotated images that are well-aligned and collected from 25K geo-locations. |
|
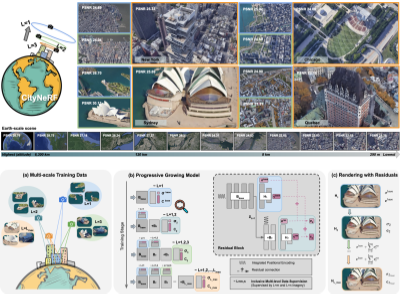
Yuanbo Xiangli*, Linning Xu*, Xingang Pan, Nanxuan Zhao, Anyi Rao, Christian Theobalt, Bo Dai, Dahua Lin ECCV, 2022 project page / paper An attempt to bring NeRF to potentially city-scale scenes, which requires rendering drastically varied observations (level-of-detail and spatial coverage) at multiscales. |
|
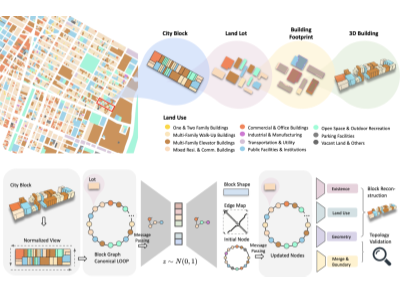
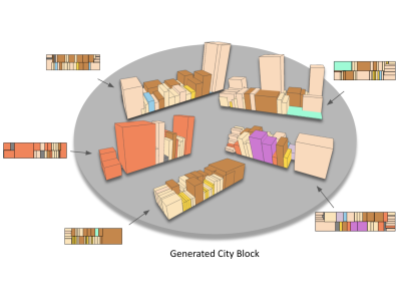
Linning Xu*, Yuanbo Xiangli*, Anyi Rao, Nanxuan Zhao, Bo Dai, Ziwei Liu, Dahua Lin ICCV, 2021 project page / paper Use graph-based VAE to automatically learn from large amount of vectorized public urban planning data for fast generation of batches of diverse and valid city block templates. |

|
Yuanbo Xiangli*, Yubin Deng*, Bo Dai*, Chen Change Loy, Dahua Lin ICLR, 2020 Spotlight code / video / paper / zhihu The proposed realness distribution provides stronger guidance to the generator and encourages it to learn more diverse outputs; enables the simplest GAN structure to synthesis high resolution portrait for the first time, with affordable computational overhead. |
|
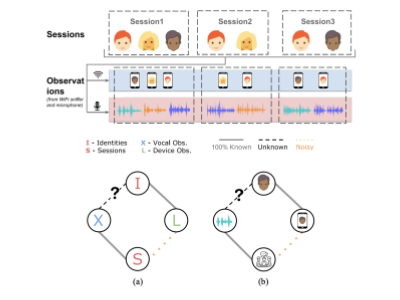
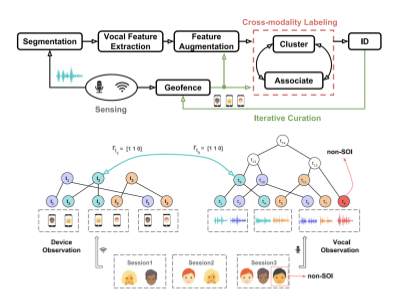
Chris Xiaoxuan Lu, Yuanbo Xiangli, Peijun Zhao, Changhao Chen, Niki Trigoni, Andrew Markham IEEE Internet Things J., 2019 HTML Yuanbo Xiangli, Chris Xiaoxuan Lu, Peijun Zhao, Changhao Chen, Andrew Markham UbiComp/ISWC Adjunct, 2019 HTML The proposed framework leverages the abundant side-channel information provided by the ubiquitous IoT environment in mordern life, enabling the construction of an in-domain speaker recognition model with zero human enrollment. |










|
The website template was borrowed from Jon Baron. Thanks for the generosity :) |